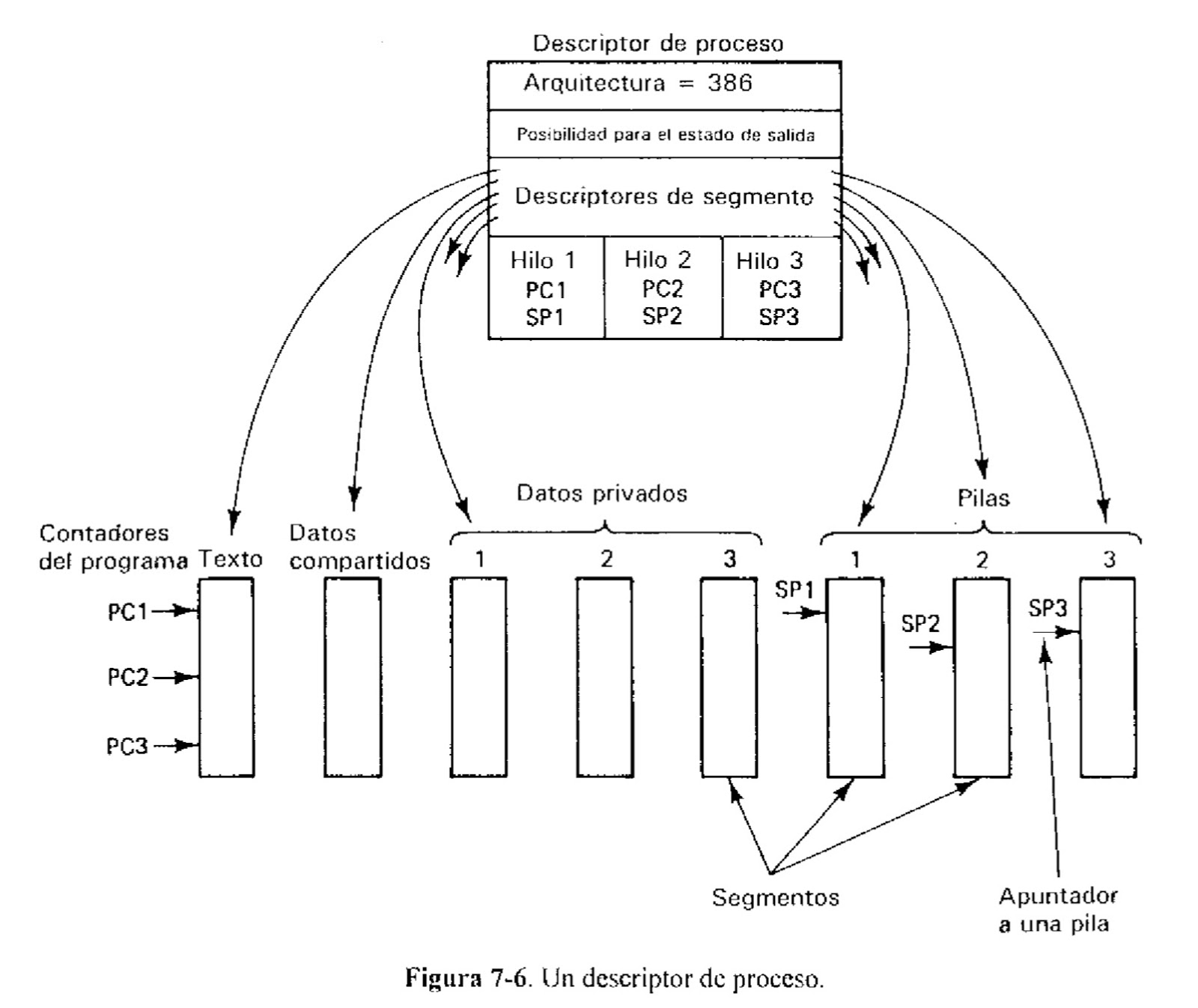
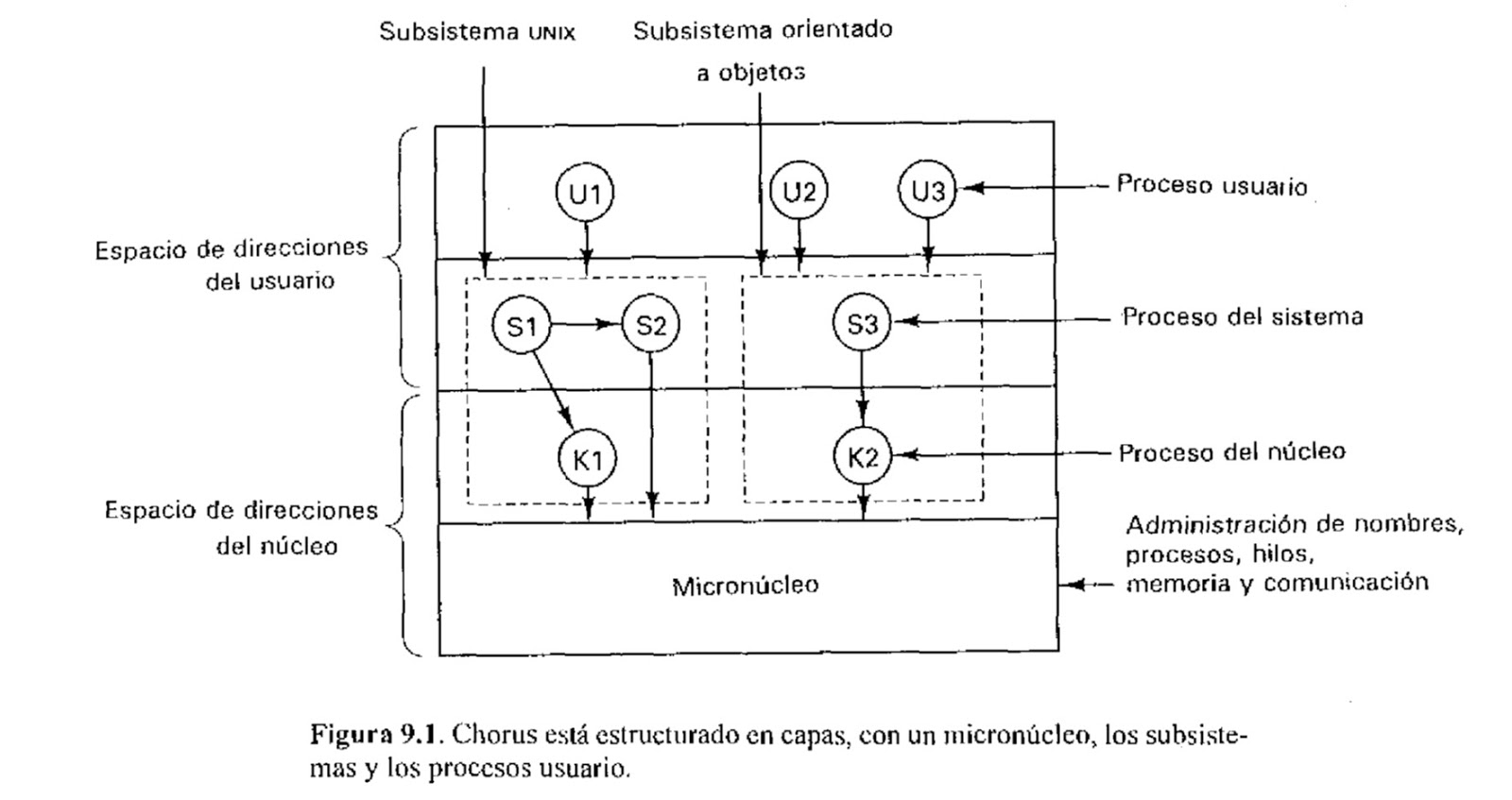
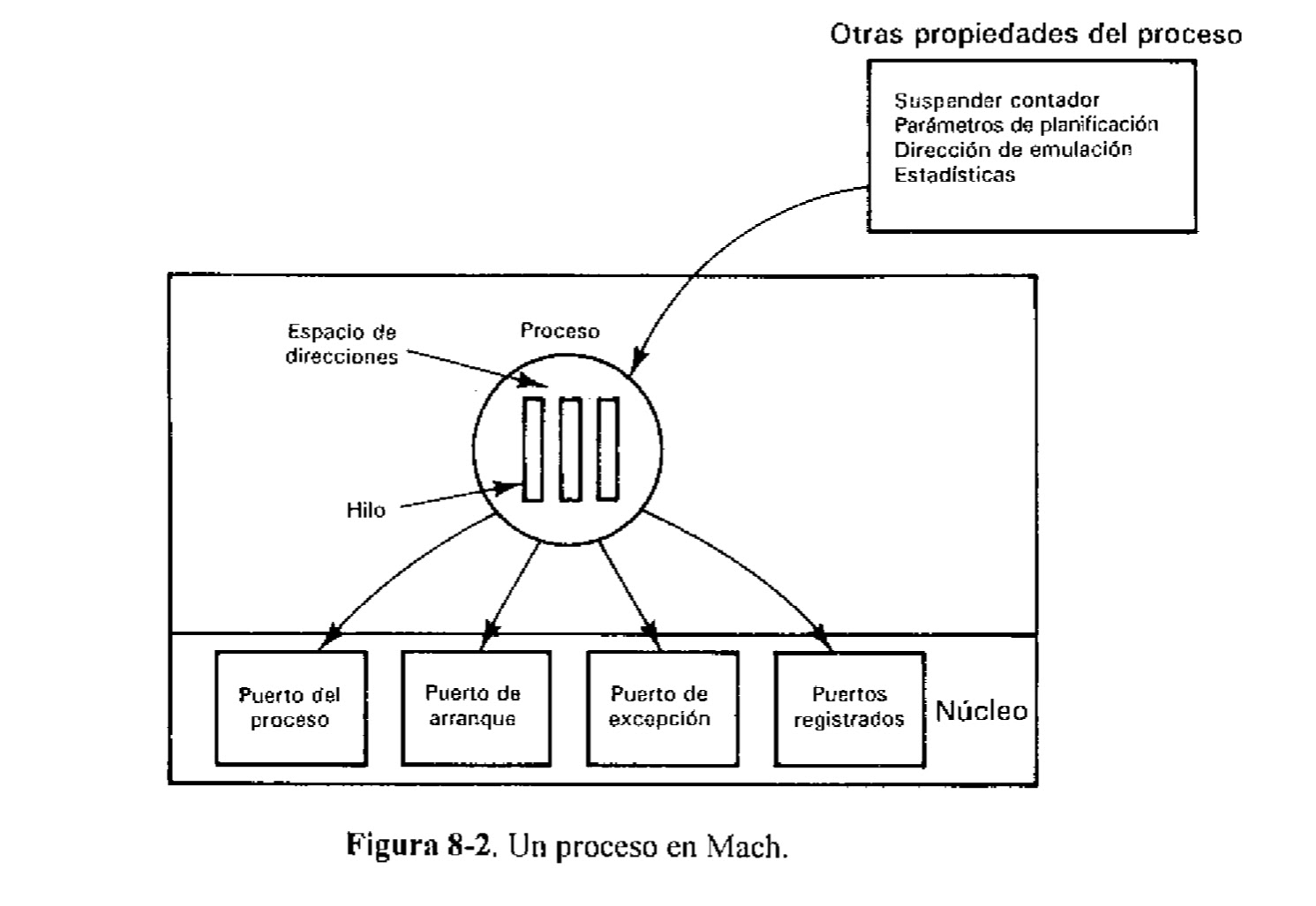
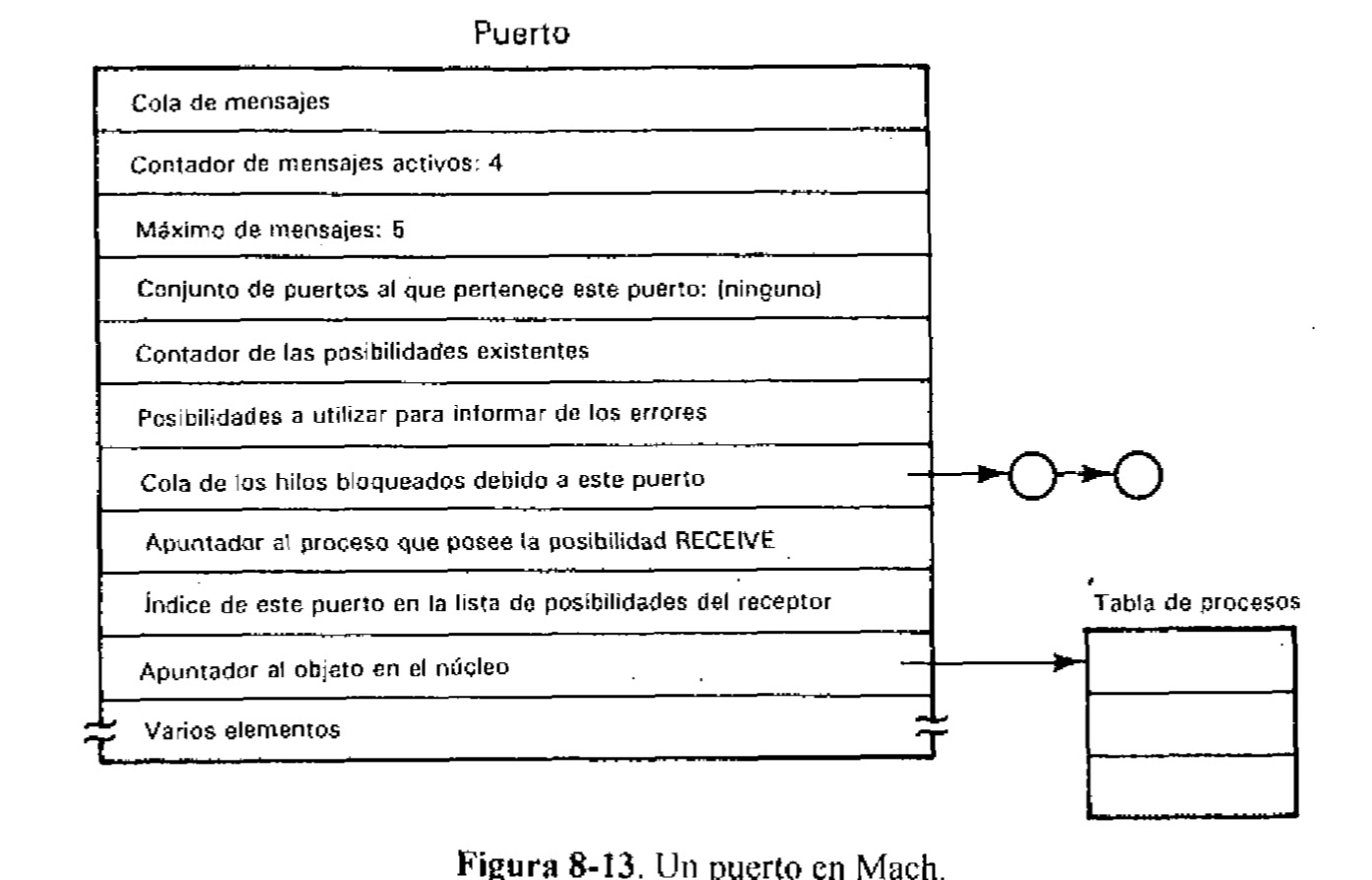
DCE
Historia de DCE
OSF fue planteada por un grupo de importantes proveedores de computadoras, entre las que estaban IBM, DEC y Hewlett-Packard, como una respuesta a la firma de un acuerdo por AT&T y Sun Microsystems para seguir desarrollando y comercializando el sistema operativo UNIX.
Objetivos de DCE
El objetivo principal de DCE es el de proporcionar un ambiente coherente, sin costuras que sirva como plataforma para la ejecución de aplicaciones distribuidas. A diferencia de Amoeba, Mach y Chorus, este ambiente se construye sobre los sistemas operativos existentes, en principio sobre UNIX, pero posteriormente fue llevado a VMS,WINDOWS y OS/2. La idea es que el cliente puede considerar una colección de máquinas existentes, añade el software DCE y después ejecuta las aplicaciones distribuidas, todo sin perturbar las aplicaciones existentes.
El sistema distribuido sobre el que se ejecuta DCE puede ser que conste de computadoras de diversos proveedores, cada una de las cuales tiene su sistema operativo local.
Componentes de DCE
El modelo de programación subyacente en todo DCE es el modelo cliente/servidor. Los procesos usuario actúan como clientes para tener acceso a los servicios remotos proporcionados por los procesos servidor. Algunos de estos servicios son parte del propio DCE, pero otros pertenecen a las aplicaciones y son escritos por los programadores de las aplicaciones.
Los principales servicios de DCE son de tiempo, directorio, seguridad y sistema de archivos.
Los principales servicios de DCE son de tiempo, directorio, seguridad y sistema de archivos.

Celdas
Los usuarios, máquinas y otros recursos en un sistema DCE se agrupan para formar celdas. La asignación de nombres, la seguridad, la administración y otros aspectos de DCE se basan en estas celdas.
Para determinar la forma de agrupar las máquinas en celdas, hay que tomar en cuenta cuatro factores:
1. Finalidad.
2. Seguridad.
3. Costo.
4. Administración.
Hilos
El paquete de hilos de DCE se basa en el estándar POSIX P 1003,4a. Es una colección de procedimientos de biblioteca a nivel usuario que permiten a los procesos crear, eliminar, y manejar hilos. Sin embargo, si el sistema anfitrión tiene un paquete de hilos, el proveedor puede configurar a DCE para utilizarlo. Las llamadas básicas permiten crear y eliminar hilos, esperar un hilo, y sincronizar el cálculo entre hilos.

Planificación
La planificación de hilos es similar a la de procesos, excepto que es visible a la aplicación. El algoritmo de planificación determina el tiempo de ejecución de cada hilo, así como el hilo que se ejecuta posteriormente. Al igual que en la planificación de procesos, se pueden construir muchos algoritmos de planificación de hilos. Los hilos en DCE tienen prioridades y éstas son respetadas por el algoritmo de planificación. Se supone que los hilos con prioridad alta son más importantes que los hilos de prioridad baja, y por lo tanto tiene un mejor tratamiento, lo que significa que se ejecutan primero y con una mayor porción del CPU.

Sincronización
DCE proporciona dos formas de sincronizar los hilos
1.- Los mútex
2.- Las variables de condición.
Los mútex se utilizan cuando es esencial evitar que varios hilos tengan acceso al mismo recurso y al mismo tiempo.
1.- Los mútex
2.- Las variables de condición.
Los mútex se utilizan cuando es esencial evitar que varios hilos tengan acceso al mismo recurso y al mismo tiempo.

Llamadas a hilos
El paquete de hilos de DCE tiene un total de 54 primitivas que son procedimientos de biblioteca. Muchas de ellas no son muy necesarias, pero se proporcionan sólo por conveniencia.

Llamadas a procedimientos remotos
Objetivos de la RPC de DCE
el sistema RPC permite que un cliente tenga acceso a un servicio remoto mediante una sencilla llamada a un procedimiento local. Esta interfaz permite escribir con facilidad los programas clientes es decir, de aplicación, de manera familiar para la mayoría de los programadores.
Estructura a un cliente y un servidor
El sistema RPC de DCE consta de varios componentes, que incluyen lenguajes, bibliotecas, demonios y programas de utilería, entre otros. Juntos permiten escribir los clientes y los servidores.

Conexión de un cliente con un servidor
Antes de que un cliente llame a un servidor, tiene que localizarlo y conectarse a él. Los usuarios ingenuos ignoran el proceso de conexión y dejan que los resguardos se encarguen de esto de manera automática, pero la conexión ocurre a pesar de todo. Los usuarios sofisticados pueden controlarla con todo detalle, para seleccionar un servidor específico en una celda distante particular. El principal problema de la conexión es la forma en que el cliente localiza al servidor correcto.
la localización del servidor se realiza en dos pasos:
1. Localizar la máquina servidor.
2. Localizar el proceso correcto en esa máquina.

Servicio de tiempo
Los datos se envían a través de una red a una computadora central para su procesamiento. Para ciertos tipos de experimentos, es esencial para el análisis que los diversos flujos de datos se sincronicen con exactitud.
Para evitar problemas con el tiempo en DCE, tiene un servicio llamado DTS (Servicio distribuido de tiempo). El objetivo de DTS es mantener sincronizados los relojes de las máquinas separadas. Sincronizarlos una vez no es suficiente, pues los cristales de los diferentes relojes vibran con tasas ligeramente diferentes, de modo que los relojes se apartan de forma gradual.
DTS debe tratar dos aspectos:
1. Mantener los relojes mutuamente consistentes.
2. Mantener los relojes en contacto con la realidad.
Modelo de tiempo DTS
En el modelo DTS el tiempo se registra como intervalos. El registro de tiempos como intervalos introduce un problema que no estaba presente en otros sistemas el cual es no siempre sirve decir esto si una hora es anterior a otra.
Cuando un programa pide a DTS que compare dos tiempos existen tres respuestas posibles:
1. El primer tiempo es anterior.
2. El segundo tiempo es anterior.
3. DTS no puede decir cuál es anterior.
El software que va a utilizar el DTS debe estar preparado para cualquier posibilidad.
Para mantener una compatibilidad con software anterior, DTS también soporta una interfaz convencional donde el tiempo se representa con un valor
Implantación de DTS
El servicio DTS consta de varias componentes como el empleado del tiempo el cual es un proceso demonio que se ejecuta en las máquinas clientes y mantiene al reloj local sincronizado con los relojes remotos.
El empleado del tiempo resincroniza al hacer contacto con todos los servidores de tiempo en su LAN. Estos son demonios cuyo trabajo es mantener el tiempo consistente y preciso dentro de límites conocidos.
Servicio de directorios
Uno de los objetivos principales de DCE es que todos los recursos son accesibles a cualquier proceso del sistema sin importar la posición relativa del usuario del recurso ni la del proveedor del recurso.
El servicio de directorios de DCE está organizado por celda, cada celda tiene un servicio de directorios de celda (CDS) que guarda los nombres y propiedades de los recursos de la celda. Este servicio está organizado como sistema distribuido de base de datos, con réplicas, para proporcionar un buen desempeño y alta disponibilidad.
Cada recurso tiene un nombre, formado por el nombre de su celda seguido por el que utiliza dentro de ella. Para localizar un recurso, el servicio de directorios necesita una forma para localizar celdas. Se soportan dos de estos mecanismos, el servicio global de directorios (GDS) y el sistema de nombres de dominio (DNS).
El servicio de directorio de celda
El CDS maneja los nombres de una celda. Éstos se ordenan como una jerarquía, aunque como en UNIX, también existen los enlaces simbólicos.
La unidad más primitiva en el sistema de directorios es la entrada de directorios de CDS, que consta de un nombre y un conjunto de atributos. La entrada para un servicio contiene el nombre del servicio, la interfaz soportada y la posición del servidor.
Servicio de seguridad
En todos los sistemas distribuidos la seguridad es importante, el administrador del sistema debe saber quien va a operar el recurso, el termino mas importante es el usuario ya que este necesita comunicarse con seguridad en los servidores y en los de aplicaciones.
La autenticación es un importante proceso para determinar si un principal es quien realmente afirma ser.
La protección en DCE está íntimamente ligada a la estructura de celdas. Cada celda tiene un servicio de seguridad en el que deben confiar los principales. El servicio de seguridad, del que es parte el servidor de autenticación, conserva las claves, las contraseñas y demás información relativa a la seguridad en una base de datos segura llamada registro.
Modelo de seguridad
La criptografia es la ciencia del envió de mensajes secretos y los requisitos e hipótesis de DCE.
 Componentes de seguridad
Componentes de seguridad
El sistema de seguridad de DCE consta de varios servidores y programas, El servidor de registro controla la base de datos de seguridad, el registro, que contiene los nombres de todos los principales, grupos y organizaciones.
EL servidor de autenticación se utiliza cuando un usuario entra al sistema o cuando se arranca un servidor, verifica la identidad afirmada del principal y emite una especie de boleto.
El servidor de autenticación también es conocido como el servidor emisor de boletos cuando está emitiendo boletos en vez de autenticar usuarios, pero estas dos funciones residen en el mismo servidor.
La facilidad de entrada es un programa que pregunta a los usuarios sus nombres y contraseñas durante la secuencia de entrada. Utiliza los servidores de autenticación y de privilegios para hacer su trabajo, que es permitir la entrada del usuario al sistema y reunir todos los boletos.
Un boleto es una estructura de datos cifrada emitida por el servidor de autenticación, o emisor de boletos para demostrar a un servidor específico que el portador es un cliente con una identidad específica.
Un autenticador es una estructura de datos cifrada que contiene al menos un emisor, suma de verificación y marca de tiempo.
ACL
ACL es una lista de control de acceso, indica quién puede tener acceso al recurso y la forma de este acceso, las ACL son controladas por los controladores de ACL, que son procedimientos de biblioteca incorporados a cada servidor.
Sistema distribuido de archivos
Es un sistema distribuido de archivos a nivel mundial que permite que los procesos dentro de un sistema DCE tengan acceso a todos los archivos que están autorizados a utilizar, aunque los procesos y los archivos estén en celdas distantes.
DFS tiene dos partes principales: la parte local y la parte de área amplia. La parte local es un sistema de archivos con un nodo llamado Episode, que es análogo a un sistema de archivos estándar de UNIX en una computadora independiente.
La parte de área amplia es el pegamento que une todos estos sistemas de archivos individuales para formar un sistema de archivos de área amplia que abarca muchas celdas.
Para evitar problemas con el tiempo en DCE, tiene un servicio llamado DTS (Servicio distribuido de tiempo). El objetivo de DTS es mantener sincronizados los relojes de las máquinas separadas. Sincronizarlos una vez no es suficiente, pues los cristales de los diferentes relojes vibran con tasas ligeramente diferentes, de modo que los relojes se apartan de forma gradual.
DTS debe tratar dos aspectos:
1. Mantener los relojes mutuamente consistentes.
2. Mantener los relojes en contacto con la realidad.
Modelo de tiempo DTS
En el modelo DTS el tiempo se registra como intervalos. El registro de tiempos como intervalos introduce un problema que no estaba presente en otros sistemas el cual es no siempre sirve decir esto si una hora es anterior a otra.
Cuando un programa pide a DTS que compare dos tiempos existen tres respuestas posibles:
1. El primer tiempo es anterior.
2. El segundo tiempo es anterior.
3. DTS no puede decir cuál es anterior.
El software que va a utilizar el DTS debe estar preparado para cualquier posibilidad.
Para mantener una compatibilidad con software anterior, DTS también soporta una interfaz convencional donde el tiempo se representa con un valor
Implantación de DTS
El servicio DTS consta de varias componentes como el empleado del tiempo el cual es un proceso demonio que se ejecuta en las máquinas clientes y mantiene al reloj local sincronizado con los relojes remotos.
El empleado del tiempo resincroniza al hacer contacto con todos los servidores de tiempo en su LAN. Estos son demonios cuyo trabajo es mantener el tiempo consistente y preciso dentro de límites conocidos.
Servicio de directorios
Uno de los objetivos principales de DCE es que todos los recursos son accesibles a cualquier proceso del sistema sin importar la posición relativa del usuario del recurso ni la del proveedor del recurso.
El servicio de directorios de DCE está organizado por celda, cada celda tiene un servicio de directorios de celda (CDS) que guarda los nombres y propiedades de los recursos de la celda. Este servicio está organizado como sistema distribuido de base de datos, con réplicas, para proporcionar un buen desempeño y alta disponibilidad.
Cada recurso tiene un nombre, formado por el nombre de su celda seguido por el que utiliza dentro de ella. Para localizar un recurso, el servicio de directorios necesita una forma para localizar celdas. Se soportan dos de estos mecanismos, el servicio global de directorios (GDS) y el sistema de nombres de dominio (DNS).
El servicio de directorio de celda
El CDS maneja los nombres de una celda. Éstos se ordenan como una jerarquía, aunque como en UNIX, también existen los enlaces simbólicos.
La unidad más primitiva en el sistema de directorios es la entrada de directorios de CDS, que consta de un nombre y un conjunto de atributos. La entrada para un servicio contiene el nombre del servicio, la interfaz soportada y la posición del servidor.
Servicio de seguridad
En todos los sistemas distribuidos la seguridad es importante, el administrador del sistema debe saber quien va a operar el recurso, el termino mas importante es el usuario ya que este necesita comunicarse con seguridad en los servidores y en los de aplicaciones.
La autenticación es un importante proceso para determinar si un principal es quien realmente afirma ser.
La protección en DCE está íntimamente ligada a la estructura de celdas. Cada celda tiene un servicio de seguridad en el que deben confiar los principales. El servicio de seguridad, del que es parte el servidor de autenticación, conserva las claves, las contraseñas y demás información relativa a la seguridad en una base de datos segura llamada registro.
Modelo de seguridad
La criptografia es la ciencia del envió de mensajes secretos y los requisitos e hipótesis de DCE.

El sistema de seguridad de DCE consta de varios servidores y programas, El servidor de registro controla la base de datos de seguridad, el registro, que contiene los nombres de todos los principales, grupos y organizaciones.
EL servidor de autenticación se utiliza cuando un usuario entra al sistema o cuando se arranca un servidor, verifica la identidad afirmada del principal y emite una especie de boleto.
El servidor de autenticación también es conocido como el servidor emisor de boletos cuando está emitiendo boletos en vez de autenticar usuarios, pero estas dos funciones residen en el mismo servidor.
La facilidad de entrada es un programa que pregunta a los usuarios sus nombres y contraseñas durante la secuencia de entrada. Utiliza los servidores de autenticación y de privilegios para hacer su trabajo, que es permitir la entrada del usuario al sistema y reunir todos los boletos.
Un boleto es una estructura de datos cifrada emitida por el servidor de autenticación, o emisor de boletos para demostrar a un servidor específico que el portador es un cliente con una identidad específica.
Un autenticador es una estructura de datos cifrada que contiene al menos un emisor, suma de verificación y marca de tiempo.
ACL
ACL es una lista de control de acceso, indica quién puede tener acceso al recurso y la forma de este acceso, las ACL son controladas por los controladores de ACL, que son procedimientos de biblioteca incorporados a cada servidor.
Sistema distribuido de archivos
Es un sistema distribuido de archivos a nivel mundial que permite que los procesos dentro de un sistema DCE tengan acceso a todos los archivos que están autorizados a utilizar, aunque los procesos y los archivos estén en celdas distantes.
DFS tiene dos partes principales: la parte local y la parte de área amplia. La parte local es un sistema de archivos con un nodo llamado Episode, que es análogo a un sistema de archivos estándar de UNIX en una computadora independiente.
La parte de área amplia es el pegamento que une todos estos sistemas de archivos individuales para formar un sistema de archivos de área amplia que abarca muchas celdas.